Dalam dunia rekayasa perangkat lunak modern, integrasi kecerdasan buatan (Artificial Intelligence) dan pembelajaran mesin (Machine Learning) ke dalam sistem produksi sudah menjadi standar baru. Salah satu metode fundamental yang paling sering digunakan adalah Regresi—yaitu memprediksi nilai kontinu (seperti estimasi harga rumah, prakiraan beban server, atau proyeksi penjualan) berdasarkan data historis.
Seringkali, insinyur perangkat lunak terbiasa melatih model secara berulang-ulang setiap kali aplikasi dijalankan. Pola ini sangat tidak efisien dan tidak berskala (not scalable). Pola arsitektur industri yang benar memisahkan fase pelatihan (training phase) dan fase penyajian (inference/serving phase). Model dilatih sekali, disimpan ke dalam penyimpanan persisten, dan kemudian dimuat ulang saat runtime untuk melakukan prediksi berlatensi rendah.
Di dalam panduan ini, kita akan merancang arsitektur jaringan saraf sederhana (Single Layer Perceptron), membedah alur pipeline produksi, serta menulis kode lengkap menggunakan TensorFlow Keras untuk melatih, mengekspor, dan memuat ulang model regresi tanpa perlu melatihnya kembali.
Arsitektur Model & Desain Sistem Produksi
Sebelum menulis kode, mari kita pahami terlebih dahulu visualisasi sistem dari Single Layer Perceptron dan siklus hidup deployment model di server produksi berikut:
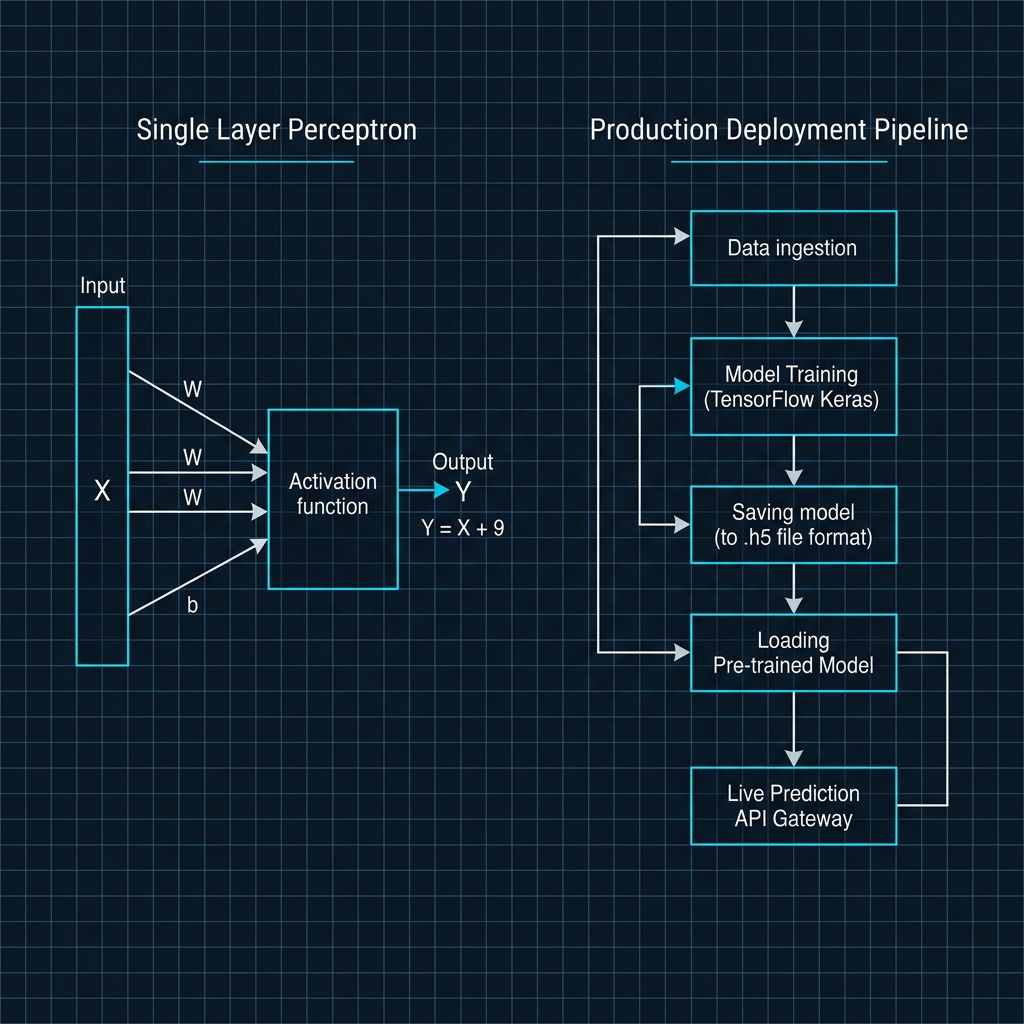
1. Arsitektur Single Layer Perceptron
Model regresi linear sederhana ini dipetakan menggunakan satu lapis jaringan saraf tiruan (Single Layer Perceptron) dengan satu neuron (unit = 1). Hubungan matematis dari input $X$ ke output $Y$ didefinisikan sebagai:
$$Y = W \cdot X + b$$
Di mana:
- $W$ (Weight / Bobot): Pengali input yang dipelajari secara otomatis oleh model selama pelatihan.
- $b$ (Bias): Nilai pergeseran konstan yang juga dipelajari model untuk meminimalkan error.
- Aktivasi (Activation Function): Karena ini adalah regresi linear murni, kita menggunakan aktivasi identitas (linear bypass) untuk langsung memetakan hasil ke output $Y$.
Pada dataset contoh kita:
- $X$ (Input):
[-4.0, -3.0, -2.0, -1.0, 0.0, 1.0, 2.0, 3.0, 4.0, 5.0] - $Y$ (Target):
[5.0, 6.0, 7.0, 8.0, 9.0, 10.0, 11.0, 12.0, 13.0, 14.0]
Jika kita perhatikan secara matematis, terdapat hubungan linear sempurna di mana setiap nilai $Y$ didapatkan dari $X + 9$ (sehingga nilai $W$ ideal adalah 1.0 dan bias $b$ ideal adalah 9.0). Jaringan saraf tiruan akan menemukan nilai parameter $W$ dan $b$ ini secara mandiri melalui optimasi Stochastic Gradient Descent (SGD).
2. Pipeline Produksi (Production Deployment Pipeline)
- Data Ingestion: Mengumpulkan data mentah, membersihkan, dan memisahkannya menjadi array NumPy numerik.
- Model Training: Melatih model TensorFlow Keras secara lokal atau di lingkungan cloud khusus GPU selama beberapa ratus epoch hingga grafik loss (Mean Squared Error) mendekati nol.
- Saving Model: Menyimpan model yang sudah matang beserta seluruh bobot ($W$ dan $b$) ke dalam berkas persisten format
.h5atau formatSavedModelbawaan Google. - Loading Pre-trained Model: Server backend memuat berkas model sekali saja ke dalam memori saat server dinyalakan pertama kali (warm start).
- Live Prediction API Gateway: Endpoint API memproses input request klien, melakukan inferensi instan menggunakan model di RAM, lalu langsung mengembalikan output JSON.
Implementasi Kode Pelatihan & Ekspor Model (Fase 1)
Berikut adalah kode Python lengkap untuk mendefinisikan model, melatihnya pada dataset linear menggunakan optimizer Stochastic Gradient Descent (SGD), mengukur nilai kerugian dengan Mean Squared Error (MSE), lalu mengekspor model ke dalam berkas persisten model_regresi.h5.
import tensorflow as tf
import numpy as np
from tensorflow import keras
# 1. Menyiapkan Dataset NumPy
X = np.array([-4.0, -3.0, -2.0, -1.0, 0.0, 1.0, 2.0, 3.0, 4.0, 5.0], dtype=float)
Y = np.array([5.0, 6.0, 7.0, 8.0, 9.0, 10.0, 11.0, 12.0, 13.0, 14.0], dtype=float)
# 2. Merancang Model Sequential (Single Layer Perceptron)
# units=1 menyatakan 1 neuron, input_shape=[1] menyatakan 1 dimensi input
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=1, input_shape=[1])
])
# 3. Mengompilasi Model dengan Optimizer SGD dan Loss Function MSE
model.compile(optimizer='sgd', loss='mean_squared_error')
# 4. Memulai Proses Pelatihan Model (Epoch = 500)
print("Memulai proses pelatihan model...")
model.fit(X, Y, epochs=500)
# 5. Melakukan Prediksi untuk Pengujian Awal
predictions = model.predict(np.array([4.0, 5.0])).round()
print(f"Hasil prediksi uji awal untuk input [4.0, 5.0]: {predictions.flatten()}")
# 6. Menyimpan Model ke Dalam Berkas Persisten HDF5 (.h5)
model_filename = 'model_regresi.h5'
model.save(model_filename)
print(f"Model berhasil diekspor secara permanen ke file: {model_filename}")
Memuat & Menggunakan Kembali Model Tanpa Pelatihan Ulang (Fase 2)
Setelah model tersimpan di media penyimpanan, kita dapat memuatnya kembali kapan saja di aplikasi web API (seperti FastAPI, Flask, atau Express.js dengan TensorFlow.js) tanpa membuang-buang waktu CPU/GPU untuk melatih model dari awal.
Berikut adalah kode inferensi yang memuat ulang model model_regresi.h5:
import tensorflow as tf
import numpy as np
# 1. Memuat Ulang Model yang Sudah Terlatih dari Berkas Persisten
model_filename = 'model_regresi.h5'
print(f"Memuat model pra-latih dari file {model_filename}...")
loaded_model = tf.keras.models.load_model(model_filename)
# Verifikasi struktur model yang dimuat
loaded_model.summary()
# 2. Menyiapkan Data Uji Baru Tanpa Melakukan Pelatihan Ulang
# Kita ingin memprediksi nilai Y untuk input X = 6.0 dan 10.0
new_data = np.array([6.0, 10.0], dtype=float)
# 3. Melakukan Inferensi Instan (Prediksi)
predictions = loaded_model.predict(new_data)
# Hubungan teoretis: Y = X + 9
# Untuk X = 6.0 -> Y seharusnya 15.0
# Untuk X = 10.0 -> Y seharusnya 19.0
print("\n==========================================")
print(" HASIL PREDIKSI REAL-TIME ")
print("==========================================")
for val, pred in zip(new_data, predictions):
print(f"Input X: {val} --> Hasil Prediksi Y: {pred[0]:.4f} (Dibulatkan: {round(pred[0])})")
print("==========================================")
Studi Kasus Riil: Memprediksi Harga Rumah Berdasarkan Luas Tanah
Dalam skenario dunia nyata, kita jarang berhadapan dengan dataset abstrak seperti $X = [-4, ..., 5]$. Mari kita terapkan sistem ini untuk memecahkan masalah riil: memprediksi harga rumah berdasarkan luas tanah.
1. Dataset Realistis
Misalkan kita memiliki data historis sebagai berikut:
- Luas Tanah ($m^2$):
[50, 60, 70, 80, 90, 100, 110, 120, 130, 150] - Harga Rumah (Juta Rupiah):
[500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1500]
Secara matematis, terdapat korelasi linear sempurna: $$\text{Harga Juta} = 10 \times \text{Luas } m^2$$ (Di mana bobot $W = 10$, artinya setiap kenaikan $1\ m^2$ luas tanah, harga bertambah 10 Juta Rupiah).
2. Pertanyaan Krusial: Mengapa Menggunakan Model ML Jika Ada Rumus Sederhana?
Sebagai seorang insinyur perangkat lunak, Anda mungkin bertanya: "Jika kita tahu rumus eksak $\text{Harga} = 10 \times \text{Luas}$, mengapa repot-repot melatih neural network?"
Jawabannya adalah prinsip kegunaan praktis (practical utility):
- Contoh Di Atas Adalah Pedagogi (Pembelajaran): Persamaan linear sederhana ini hanyalah sebuah analogi agar kita mudah memahami bagaimana sebuah neuron tunggal (Single Layer Perceptron) melakukan kalkulasi optimasi gradien untuk mencari parameter bobot ($W$) dan bias ($b$) secara mandiri dari data.
- Kompleksitas Dunia Nyata (Nonlinear): Di lapangan, harga rumah dipengaruhi oleh ratusan variabel lain yang saling tumpang tindih secara non-linear (misal: koordinat lokasi, usia bangunan, jumlah kamar tidur, lebar jalan, hingga inflasi). Merumuskan persamaan matematika secara manual untuk relasi sekompleks itu adalah hal yang hampir mustahil dilakukan manusia.
- Data Penuh Noise (Inkonsistensi): Data asli sangat bervariasi dan tidak konsisten. Model ML bertugas mencari kurva tren terbaik (best-fit curve) yang paling meminimalkan rata-rata kesalahan (loss) dari ribuan data historis yang tidak sempurna tersebut.
- Adaptabilitas Tren Baru: Ketika tren pasar bergeser (misal terjadi resesi atau booming properti), kita tidak perlu membongkar baris logika kode program kita secara manual. Kita cukup melakukan pelatihan ulang (fine-tuning) model menggunakan data transaksi teranyar, dan model akan beradaptasi secara otomatis.
3. Tantangan Skala Data (Exploding Gradients)
Jika kita memasukkan data bernilai besar (seperti 100 dan 1000) langsung ke optimizer sgd dengan parameter default, gradien akan meledak (exploding gradients) dan fungsi loss akan menghasilkan nilai NaN (Not a Number).
Untuk mengatasinya, kita memiliki dua strategi rekayasa:
- Data Scaling (Normalisasi): Membagi input $X$ dengan 100 (dalam ratusan $m^2$) dan $Y$ dengan 100 (dalam ratusan Juta Rupiah) agar nilainya berkisar antara 0.5 hingga 15.0.
- Learning Rate Tuning: Memperkecil langkah optimizer, misalnya menggunakan learning rate
0.0001alih-alih nilai bawaan0.01.
Berikut adalah kode implementasi stabil dengan Data Scaling:
import tensorflow as tf
import numpy as np
# 1. Dataset Riil (Telah Diskala agar Pelatihan Stabil)
# Luas tanah (dibagi 100) -> 0.5 berarti 50 m2, 1.5 berarti 150 m2
X_house = np.array([0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2, 1.3, 1.5], dtype=float)
# Harga rumah (dibagi 100) -> 5.0 berarti 500 Juta, 15.0 berarti 1.5 Miliar
Y_house = np.array([5.0, 6.0, 7.0, 8.0, 9.0, 10.0, 11.0, 12.0, 13.0, 15.0], dtype=float)
# 2. Inisialisasi Model Sequential
house_model = tf.keras.Sequential([
tf.keras.layers.Dense(units=1, input_shape=[1])
])
# 3. Compile Model dengan Learning Rate Kustom untuk Stabilitas Ekstrim
house_model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.01), loss='mean_squared_error')
# 4. Pelatihan Model
print("Melatih model harga rumah...")
house_model.fit(X_house, Y_house, epochs=500, verbose=0) # verbose=0 untuk output bersih
# 5. Ekspor Model Harga Rumah
house_model.save('model_harga_rumah.h5')
print("Model harga rumah berhasil diekspor!")
# 6. Memuat Kembali dan Melakukan Inferensi Data Baru
# Kita ingin memprediksi harga rumah untuk luas tanah 140 m2 (skala 1.4)
loaded_house_model = tf.keras.models.load_model('model_harga_rumah.h5')
new_area = np.array([1.4], dtype=float)
predicted_scaled = loaded_house_model.predict(new_area)
predicted_actual_juta = predicted_scaled[0][0] * 100 # Dikembalikan ke skala asal (Juta Rupiah)
print("\n==========================================")
print(" PREDIKSI HARGA RUMAH (STUDI KASUS) ")
print("==========================================")
print(f"Luas Tanah Baru : 140 m2")
print(f"Hasil Estimasi : {predicted_actual_juta:.2f} Juta Rupiah")
print(f"Pembulatan : {round(predicted_actual_juta)} Juta Rupiah")
print("==========================================")
Strategi Optimasi & Deployment di Server Produksi
Agar sistem prediksi ini siap melayani jutaan transaksi di lingkungan production:
- Lakukan Pre-Loading Model (Warm Start):
Jangan pernah memanggil fungsi
load_model()di dalam fungsi penangan rute endpoint API (seperti di dalam blok rute API endpoint Flask/FastAPI). Proses pembacaan file dari disk dan inisialisasi arsitektur jaringan saraf di memori memakan latensi I/O yang sangat mahal. Muat model sebagai variabel global sekali saja saat server API pertama kali dihidupkan (startup event). - Optimasi Ukuran File (TensorFlow Lite):
Untuk menghemat kapasitas server atau dijalankan di perangkat mikro/IoT/aplikasi seluler, konversikan model
.h5ke format TensorFlow Lite (.tflite) menggunakan TFLiteConverter. Ini akan mereduksi ukuran file model hingga 4x lipat dan memangkas waktu inferensi milidetik menjadi mikrodetik. - Gunakan TensorFlow Serving untuk Horizontal Scaling: Jika sistem Anda sangat besar, hindari membungkus model Keras di dalam API Python buatan sendiri. Gunakan TensorFlow Serving di dalam Docker Container. TensorFlow Serving dirancang oleh Google khusus untuk menyajikan model machine learning dengan performa C++ tingkat tinggi, mendukung auto-batching request, rotasi versi model otomatis tanpa downtime, serta mendukung protokol berkecepatan tinggi gRPC.
Kesimpulan Ringkas
Pemisahan arsitektur antara fase pelatihan (training) dan penyajian (inference) adalah kunci membangun sistem machine learning yang andal dan terukur. Dengan melatih model sekali menggunakan TensorFlow Keras, menyimpannya dalam berkas .h5, dan menyajikannya secara efisien menggunakan strategi pra-muat memori, Anda dapat melahirkan sistem prediksi waktu nyata berlatensi rendah yang siap menopang jutaan data di platform produksi!