Pernahkah kamu penasaran bagaimana fitur pencarian di aplikasi skala menengah bekerja di balik layar? Mengetik kata kunci, dan tiba-tiba aplikasi menyuguhkan hasil pencarian yang relevan, lengkap dengan skor kemiripan.
Bagi banyak pengembang, solusi instan seperti Elasticsearch atau Algolia sering kali menjadi pilihan utama. Namun, jika kamu ingin membangun mesin pencari (search engine) yang ringan, hemat biaya, dan terintegrasi langsung dengan database relasionalmu tanpa overhead infrastruktur baru, algoritma TF-IDF (Term Frequency-Inverse Document Frequency) yang dipadukan dengan PostgreSQL adalah kombinasi yang menarik.
Artikel ini akan memandu kamu dari sisi arsitektur, kalkulasi matematika sederhana, skema database PostgreSQL, hingga implementasi kode menggunakan TypeScript.
1. Arsitektur Sistem Mesin Pencari TF-IDF
Sebelum masuk ke baris kode, mari kita pahami gambaran besar bagaimana data mengalir di dalam sistem. Mesin pencari terbagi menjadi dua jalur utama: Ingestion Pipeline (proses pengindeksan dokumen) dan Query Pipeline (proses pencarian oleh pengguna).
Berikut adalah blueprint arsitektur sistem mesin pencari berbasis TF-IDF:
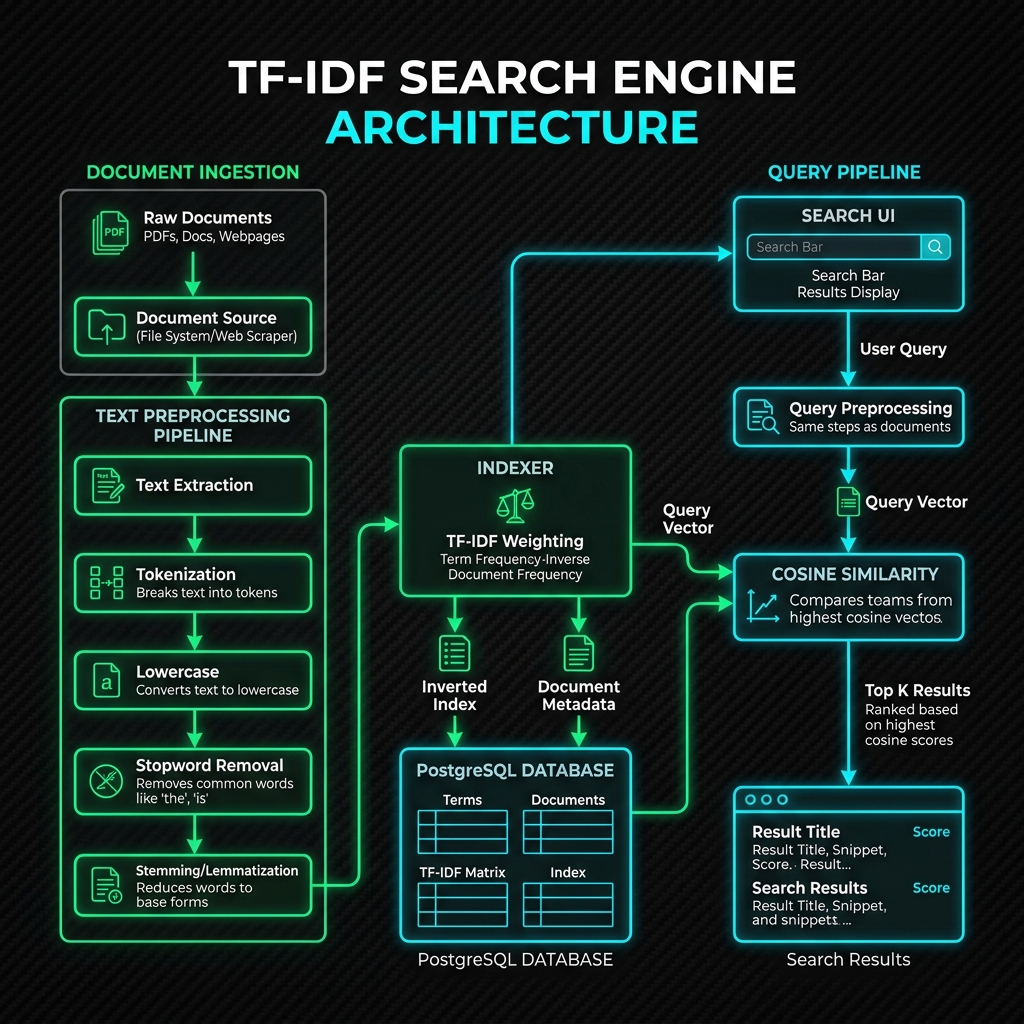
Jalur 1: Ingestion & Indexing Pipeline
- Document Extraction: Mengambil teks mentah dari berbagai sumber dokumen (PDF, halaman web, database).
- Text Preprocessing: Teks dibersihkan melalui beberapa tahap pemrosesan data:
- Tokenization: Memecah kalimat panjang menjadi potongan kata (tokens).
- Normalization (Lowercase): Mengubah huruf kapital menjadi huruf kecil agar tidak sensitif kasus.
- Stopword Removal: Membuang kata-kata umum yang tidak memiliki nilai informasi unik (misalnya: "yang", "dan", "di", "dari", "dengan", "ke", "ini", "itu", "atau", "the", "is", "at", "which", "on", "for", "a", "an", "in", "to").
- Stemming: Memotong imbuhan kata untuk mengembalikannya ke bentuk dasar (misalnya: "memakan" -> "makan").
- TF-IDF Weighting: Menghitung bobot kepentingan tiap istilah (term) pada setiap dokumen.
- Database Storage: Menyimpan bobot tersebut ke dalam tabel indeks terbalik (inverted index) di PostgreSQL.
Jalur 2: Query & Retrieval Pipeline
- User Query: Pengguna memasukkan kata kunci pencarian pada Search UI.
- Query Preprocessing: Melakukan langkah pembersihan teks yang persis sama dengan dokumen (tokenization, lowercase, stopword removal, stemming).
- Vector Construction: Membentuk representasi vektor dari kata kunci pencarian.
- Cosine Similarity: Menghitung sudut kosinus antara vektor pencarian dengan vektor dokumen yang ada di database. Dokumen dengan arah vektor yang paling mendekati vektor pencarian akan mendapatkan skor tertinggi.
- Ranking: Mengurutkan dokumen berdasarkan skor tertinggi dan menampilkannya kepada pengguna.
2. Memahami Logika Matematika TF-IDF
TF-IDF adalah metrik statistik yang digunakan untuk mengukur seberapa penting suatu kata (term) dalam sebuah dokumen di tengah kumpulan dokumen (corpus).
Berikut adalah alur logika matematika dan cara kerja sistem dalam menghitung relevansi dokumen:
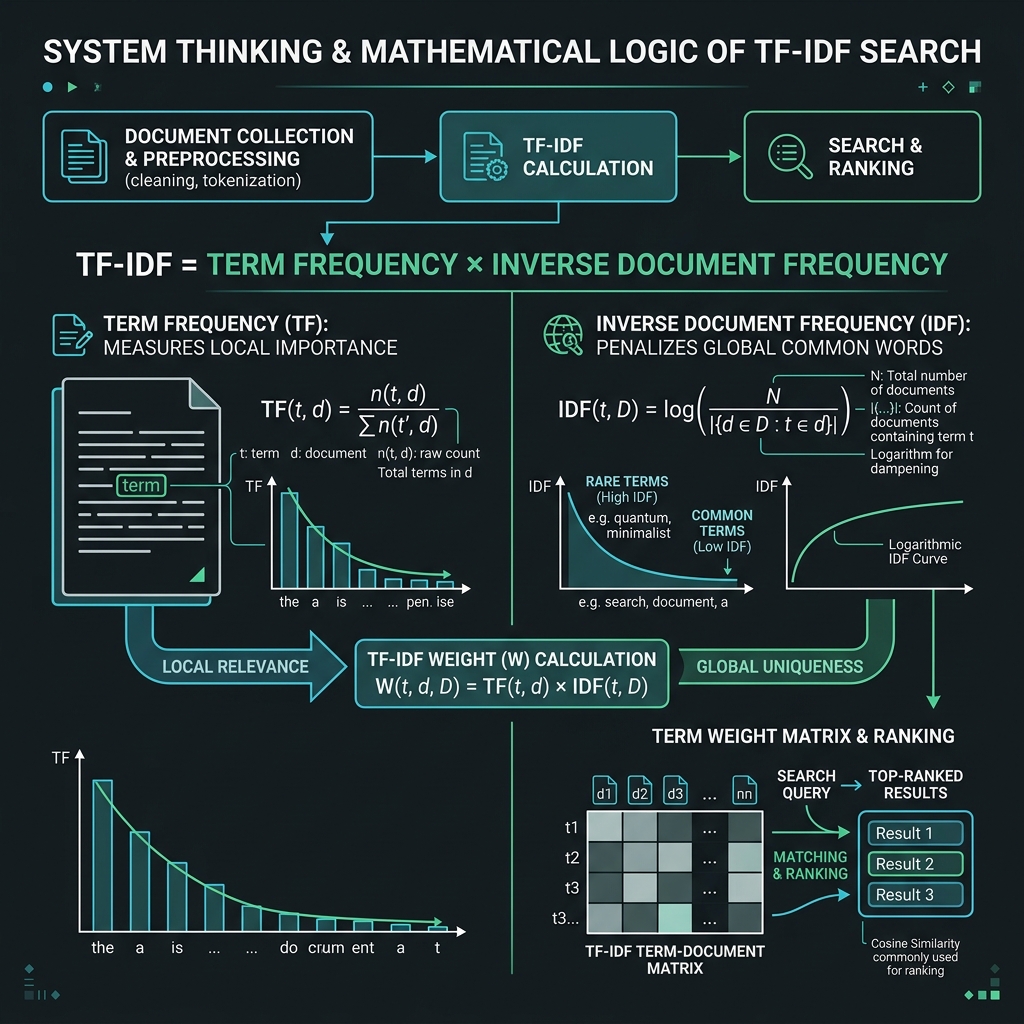
Logika utama TF-IDF dibagi menjadi dua komponen:
A. Term Frequency (TF)
Mengukur seberapa sering sebuah kata muncul di dalam satu dokumen tertentu. Asumsinya: semakin sering kata tersebut muncul, semakin relevan dokumen tersebut terhadap kata kunci. $$TF(t, d) = \frac{\text{Jumlah kemunculan kata } t \text{ di dokumen } d}{\text{Total kata di dokumen } d}$$
B. Inverse Document Frequency (IDF)
Mengukur keunikan suatu kata secara global di seluruh dokumen. Kata yang muncul di hampir semua dokumen (seperti kata sambung) nilainya akan diturunkan, sedangkan kata yang langka (seperti nama merek atau istilah teknis) bobotnya akan ditingkatkan. $$IDF(t, D) = \log\left(\frac{\text{Total jumlah dokumen } N}{\text{Jumlah dokumen yang mengandung kata } t}\right)$$
C. TF-IDF Weight Calculation
Bobot akhir didapatkan dengan mengalikan nilai TF dengan IDF: $$W(t, d, D) = TF(t, d) \times IDF(t, D)$$
Melalui perkalian ini, kita mendapatkan Vector Space Model di mana setiap dokumen direpresentasikan sebagai titik-titik koordinat multi-dimensi. Sudut antar vektor inilah yang kemudian kita hitung menggunakan Cosine Similarity: $$\text{Similarity}(Q, D) = \frac{Q \cdot D}{|Q| |D|}$$
3. Merancang Skema Database di PostgreSQL
PostgreSQL sangat andal untuk menyimpan struktur matriks TF-IDF. Kita akan membuat tiga tabel utama:
documents: Menyimpan dokumen mentah.dictionary: Menyimpan daftar kata unik yang sudah dibersihkan secara global.inverted_index: Tabel penghubung untuk menyimpan bobot TF-IDF dari kata tertentu pada dokumen tertentu.
Berikut adalah skema SQL yang bisa kamu gunakan:
-- Menyimpan dokumen asli
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
title VARCHAR(255) NOT NULL,
content TEXT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Menyimpan vocabulary unik secara global beserta nilai IDF-nya
CREATE TABLE dictionary (
term VARCHAR(100) PRIMARY KEY,
document_count INT DEFAULT 1,
idf DOUBLE PRECISION DEFAULT 0.0
);
-- Menyimpan inverted index dengan bobot TF-IDF tiap term di tiap dokumen
CREATE TABLE inverted_index (
document_id INT REFERENCES documents(id) ON DELETE CASCADE,
term VARCHAR(100) REFERENCES dictionary(term) ON DELETE CASCADE,
tf DOUBLE PRECISION NOT NULL,
tfidf DOUBLE PRECISION NOT NULL,
PRIMARY KEY (document_id, term)
);
-- Indexing untuk query pencarian yang cepat
CREATE INDEX idx_inverted_index_term ON inverted_index(term);
4. Implementasi Kode Preprocessing & Indexer (TypeScript)
Berikut adalah contoh implementasi modul pengindeksan teks menggunakan TypeScript. Kita akan membuat class pencari sederhana yang menangani preprocessing hingga penyimpanan data ke database.
Modul Preprocessing Teks
import { Client } from 'pg';
export class TextPreprocessor {
// Daftar stopwords sederhana bahasa Indonesia & Inggris
private static readonly STOPWORDS = new Set([
'yang', 'dan', 'di', 'dari', 'dengan', 'ke', 'ini', 'itu', 'atau',
'the', 'is', 'at', 'which', 'on', 'for', 'a', 'an', 'in', 'to'
]);
public static clean(text: string): string[] {
return text
.toLowerCase()
.replace(/[^a-zA-Z0-9\s]/g, '') // Menghapus tanda baca
.split(/\s+/) // Tokenization berdasarkan spasi
.filter(token => token.length > 1 && !this.STOPWORDS.has(token)); // Stopword removal
}
}
Modul Pengindeks Dokumen (Indexer)
export class SearchIndexer {
private db: Client;
constructor(dbClient: Client) {
this.db = dbClient;
}
// Menyimpan dokumen baru dan menghitung ulang bobot TF-IDF
public async indexDocument(title: string, content: string): Promise<void> {
// 1. Simpan dokumen asli
const docResult = await this.db.query(
'INSERT INTO documents (title, content) VALUES ($1, $2) RETURNING id',
[title, content]
);
const docId = docResult.rows[0].id;
// 2. Lakukan Preprocessing
const tokens = TextPreprocessor.clean(content);
const totalTokens = tokens.length;
if (totalTokens === 0) return;
// Hitung frekuensi mentah tiap token (Raw Term Frequency)
const termCounts: Record<string, number> = {};
for (const token of tokens) {
termCounts[token] = (termCounts[token] || 0) + 1;
}
// 3. Simpan kosakata ke dictionary dan hitung TF
for (const [term, count] of Object.entries(termCounts)) {
const tf = count / totalTokens;
// Update dictionary global (UPSERT)
await this.db.query(
`INSERT INTO dictionary (term, document_count)
VALUES ($1, 1)
ON CONFLICT (term)
DO UPDATE SET document_count = dictionary.document_count + 1`,
[term]
);
// Simpan nilai TF sementara ke inverted index
await this.db.query(
`INSERT INTO inverted_index (document_id, term, tf, tfidf)
VALUES ($1, $2, $3, 0.0)`,
[docId, term, tf]
);
}
// 4. Hitung ulang IDF global dan perbarui nilai TF-IDF matriks
await this.recalculateTfidf();
}
private async recalculateTfidf(): Promise<void> {
// Ambil total seluruh dokumen (N)
const totalDocsResult = await this.db.query('SELECT COUNT(*) as count FROM documents');
const N = parseInt(totalDocsResult.rows[0].count);
if (N === 0) return;
// Perbarui nilai IDF pada dictionary
await this.db.query(
`UPDATE dictionary SET idf = ln($1::double precision / document_count::double precision)`,
[N]
);
// Perbarui nilai TF-IDF matriks pada inverted_index
await this.db.query(
`UPDATE inverted_index ii
SET tfidf = ii.tf * d.idf
FROM dictionary d
WHERE ii.term = d.term`
);
}
}
5. Implementasi Algoritma Pencarian & Cosine Similarity
Saat pengguna mengetik kueri, kita akan memproses kueri tersebut menjadi vektor kueri, lalu menghitung kemiripannya dengan dokumen-dokumen di database menggunakan rumus matematis yang diterjemahkan ke dalam query SQL performa tinggi.
Berikut adalah gambaran langkah kalkulasi pencarian:
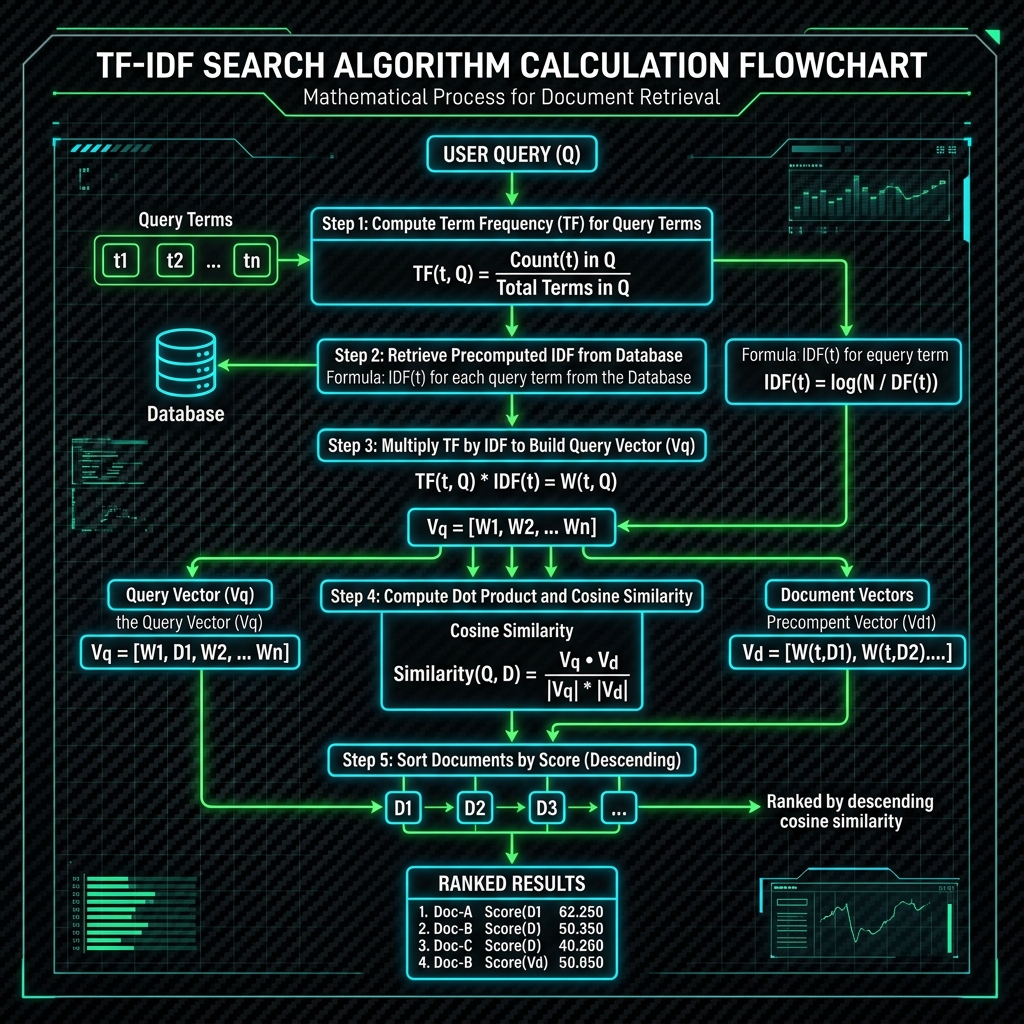
Kita dapat menggabungkan kalkulasi dot product dan pencocokan vektor ini dalam satu fungsi pencarian TypeScript yang mengeksekusi raw query SQL yang sangat cepat:
export interface SearchResult {
documentId: number;
title: string;
content: string;
score: number;
}
export class SearchEngine {
private db: Client;
constructor(dbClient: Client) {
this.db = dbClient;
}
public async search(queryText: string, limit: number = 5): Promise<SearchResult[]> {
const queryTokens = TextPreprocessor.clean(queryText);
if (queryTokens.length === 0) return [];
// Hitung TF kueri
const queryTermCounts: Record<string, number> = {};
for (const token of queryTokens) {
queryTermCounts[token] = (queryTermCounts[token] || 0) + 1;
}
const totalQueryTerms = queryTokens.length;
const queryVectors: Array<{ term: string; weight: number }> = [];
// Bangun bobot vektor kueri menggunakan IDF dari database
for (const [term, count] of Object.entries(queryTermCounts)) {
const tf = count / totalQueryTerms;
const dictResult = await this.db.query('SELECT idf FROM dictionary WHERE term = $1', [term]);
const idf = dictResult.rows.length > 0 ? parseFloat(dictResult.rows[0].idf) : 0.0;
queryVectors.push({ term, weight: tf * idf });
}
// Bangun query SQL Cosine Similarity menggunakan CTE (Common Table Expressions)
const terms = queryVectors.map(v => v.term);
const weights = queryVectors.map(v => v.weight);
const sqlQuery = `
WITH query_vector AS (
SELECT unnest($1::text[]) AS term, unnest($2::double precision[]) AS weight
),
document_scores AS (
SELECT
ii.document_id,
-- Dot Product: Q . D
SUM(qv.weight * ii.tfidf) AS dot_product,
-- Magnitude Document: |D|
SUM(ii.tfidf * ii.tfidf) AS doc_magnitude_sq
FROM inverted_index ii
JOIN query_vector qv ON ii.term = qv.term
GROUP BY ii.document_id
),
query_magnitude AS (
-- Magnitude Query: |Q|
SELECT SQRT(SUM(weight * weight)) AS q_mag FROM query_vector
)
SELECT
d.id,
d.title,
d.content,
-- Cosine Similarity Score = (Q . D) / (|Q| * |D|)
(ds.dot_product / (qm.q_mag * SQRT(ds.doc_magnitude_sq))) AS score
FROM document_scores ds
JOIN documents d ON ds.document_id = d.id
CROSS JOIN query_magnitude qm
ORDER BY score DESC
LIMIT $3;
`;
const result = await this.db.query(sqlQuery, [terms, weights, limit]);
return result.rows.map(row => ({
documentId: row.id,
title: row.title,
content: row.content,
score: parseFloat(row.score)
}));
}
}
6. Desain UI Antarmuka Pencarian Modern
Agar performa mesin pencari buatanmu terasa premium, desain antarmuka (User Interface) harus dirancang secara bersih dengan aksen modern menggunakan TailwindCSS.
Berikut adalah rancangan antarmuka pencarian modern lengkap dengan visualisasi bobot token kueri real-time:

Rancangan antarmuka di atas bisa diimplementasikan secara statis menggunakan TailwindCSS:
<div class="min-h-screen bg-neutral-950 text-neutral-100 p-8 font-sans">
<div class="max-w-3xl mx-auto space-y-6">
<!-- Header -->
<header class="text-center py-6">
<h1 class="text-3xl font-extrabold tracking-tight bg-gradient-to-r from-cyan-400 to-emerald-400 bg-clip-text text-transparent">
QUANTUM SEARCH
</h1>
<p class="text-neutral-400 text-sm mt-2">Mesin pencari berbasis TF-IDF Vector Space Model</p>
</header>
<!-- Search Input Area -->
<div class="relative group">
<div class="absolute -inset-0.5 bg-gradient-to-r from-cyan-500 to-emerald-500 rounded-lg blur opacity-30 group-hover:opacity-60 transition duration-300"></div>
<div class="relative flex items-center bg-neutral-900 border border-neutral-800 rounded-lg p-3">
<svg class="w-6 h-6 text-neutral-400 mr-3" fill="none" stroke="currentColor" viewBox="0 0 24 24">
<path stroke-linecap="round" stroke-linejoin="round" stroke-width="2" d="M21 21l-6-6m2-5a7 7 0 11-14 0 7 7 0 0114 0z"/>
</svg>
<input
type="text"
placeholder="Ketik kata kunci pencarian..."
class="w-full bg-transparent text-lg text-white placeholder-neutral-500 focus:outline-none"
/>
</div>
</div>
<!-- Real-time Tokenization Weights -->
<div class="bg-neutral-900/50 border border-neutral-900 rounded-lg p-4 space-y-3">
<h3 class="text-xs font-semibold text-neutral-400 uppercase tracking-wider">Real-time Tokenization & Term Weights</h3>
<div class="grid grid-cols-4 gap-4">
<div class="bg-neutral-900 p-3 rounded-lg border border-neutral-800 text-xs">
<p class="font-bold text-emerald-400">quantum</p>
<div class="mt-2 space-y-1 text-neutral-500">
<p>TF: <span class="text-neutral-300">0.15</span></p>
<p>IDF: <span class="text-neutral-300">3.12</span></p>
<p class="text-cyan-400 font-semibold">Weight: 0.468</p>
</div>
</div>
<!-- Tambahkan token lainnya secara dinamis -->
</div>
</div>
<!-- Search Results -->
<div class="space-y-4">
<div class="bg-neutral-900 border border-neutral-950 p-5 rounded-lg flex gap-6 hover:border-neutral-800 transition duration-200">
<!-- Relevancy Score -->
<div class="flex-shrink-0 flex items-center justify-center bg-emerald-950/50 text-emerald-400 font-mono font-bold text-lg w-16 h-16 rounded-lg border border-emerald-900/50">
0.945
</div>
<!-- Document Snippet -->
<div class="space-y-2">
<h2 class="text-lg font-bold text-white hover:text-cyan-400 cursor-pointer transition">
Explaining Quantum Computing and Machine Learning
</h2>
<p class="text-neutral-400 text-sm leading-relaxed">
...bagaimana algoritma <span class="text-emerald-400 font-semibold">quantum computing</span> dapat meningkatkan performa model <span class="text-emerald-400 font-semibold">machine learning</span> untuk optimasi komputasi kompleks...
</p>
<div class="flex items-center text-xs text-neutral-500 space-x-3 pt-1">
<span>Source: arXiv</span>
<span>•</span>
<span>Published: Oct 26, 2023</span>
</div>
</div>
</div>
</div>
</div>
</div>
7. Kelebihan & Batasan Mesin Pencari TF-IDF
Meskipun TF-IDF sangat mudah dibangun dan tidak memerlukan server pencarian eksternal, penting untuk mengetahui kapan harus menggunakannya:
| Fitur / Parameter | Kelebihan & Penggunaan | Batasan & Kelemahan |
|---|---|---|
| Resource Overhead | Sangat ringan, terintegrasi langsung dengan query SQL database PostgreSQL. | Bobot dokumen harus terus dihitung ulang (recalculated) saat dokumen baru ditambahkan. |
| Pencarian Semantik | Sangat baik untuk pencocokan kata kunci eksak secara literal (exact keyword matching). | Tidak memahami sinonim atau konteks kata (misalnya: kueri "mobil" tidak akan mencocokkan dokumen berisi kata "kendaraan"). |
| Kueri Pendek | Sangat cepat untuk kueri sederhana beranggotakan 1-3 kata kunci. | Rentan terhadap manipulasi dokumen yang dipadati pengulangan kata kunci yang sama (keyword stuffing). |
Untuk mengatasi batasan pemahaman kata kunci yang tidak eksak, kamu dapat mengkombinasikan TF-IDF dengan fitur PostgreSQL Full-Text Search (FTS) menggunakan modul tsvector dan tsquery bawaan PostgreSQL yang mendukung pencocokan linguistik tingkat lanjut.
Selamat membangun mesin pencarimu sendiri! Dengan memahami dasar-dasar matematika di balik TF-IDF dan kalkulasi vektor space model, kamu kini memiliki dasar yang kuat untuk melangkah ke teknologi pencarian berbasis AI seperti Vector Embeddings dan Semantic Search.