Dalam dunia e-commerce, fitur pencarian produk (product search) adalah jantung dari konversi penjualan. Pengguna yang mengetikkan kata kunci pencarian seperti "wireless gaming mouse" memiliki intensi membeli yang sangat tinggi. Jika mesin pencari gagal menampilkan produk yang paling relevan di halaman pertama, potensi transaksi dapat hilang seketika.
Meskipun algoritma dasar seperti TF-IDF cukup baik untuk pencarian teks umum, algoritma ini memiliki keterbatasan besar pada e-commerce: TF-IDF rentan terhadap manipulasi jumlah kata (keyword stuffing) dan tidak memperhitungkan variasi panjang deskripsi produk secara proporsional.
Sebagai solusinya, industri mesin pencari modern menggunakan Okapi BM25 (Best Matching 25)—algoritma pencarian probabilistik legendaris yang juga mendasari mesin pencari kelas atas seperti Elasticsearch dan Lucene.
Artikel ini akan mengupas tuntas arsitektur sistem, dasar matematika BM25, skema database PostgreSQL, hingga implementasi kode pencarian produk e-commerce menggunakan TypeScript dan antarmuka TailwindCSS.
1. Arsitektur Mesin Pencari Produk E-Commerce
Mesin pencari produk e-commerce harus bekerja dengan latensi rendah sambil memproses data dinamis seperti nama produk, deskripsi, harga, stok, dan kategori.
Berikut adalah cetak biru arsitektur sistem mesin pencari e-commerce berbasis Okapi BM25:
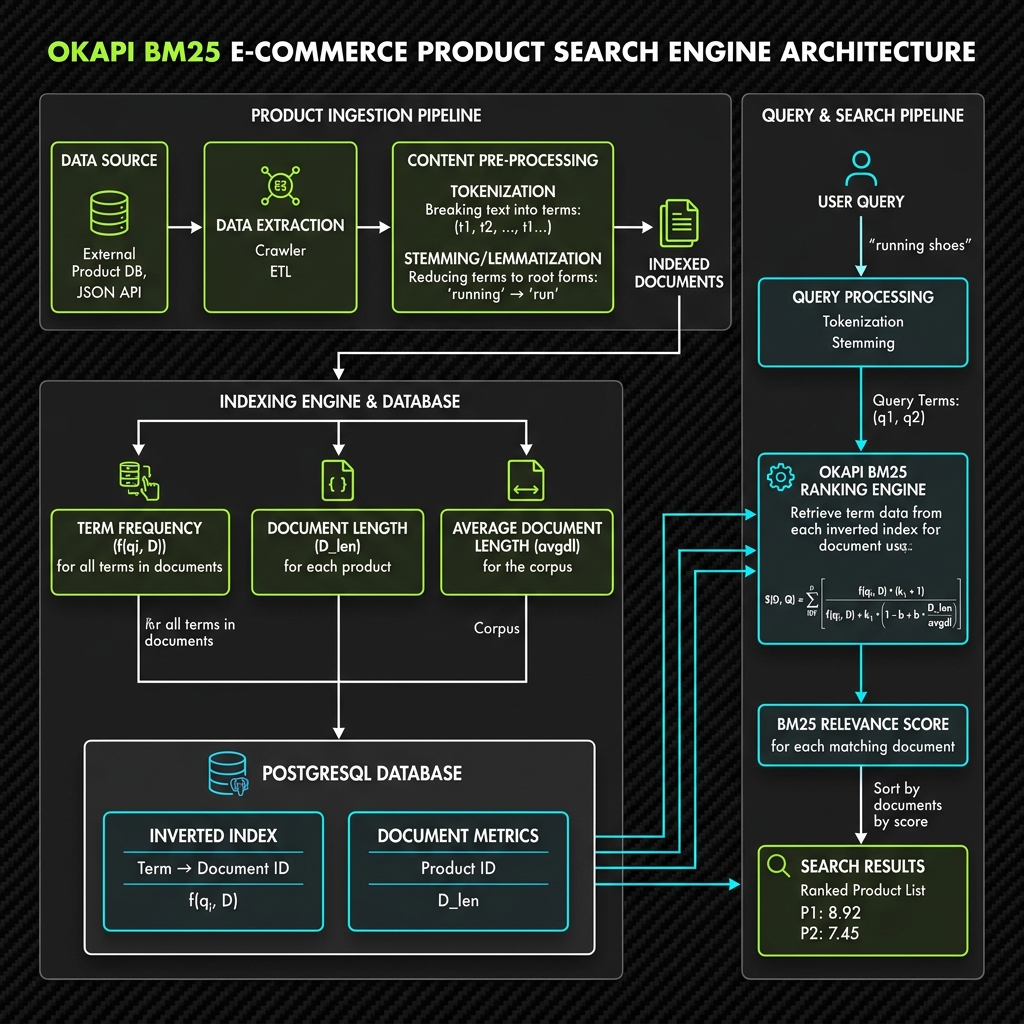
Alur Kerja Sistem:
Product Ingestion Pipeline:
- Mengambil data produk dari database operasional atau inventaris inventori.
- Melakukan pembersihan teks (preprocessing) pada nama dan deskripsi produk melalui tahap Tokenization (pemecahan kata), Stopword Removal (pembuangan kata hubung), dan Stemming (pemotongan imbuhan kata menjadi kata dasar).
- Menghitung parameter khusus dokumen: Document Length (jumlah kata unik dalam suatu produk) dan memperbarui Average Document Length (avgdl) (panjang rata-rata deskripsi produk di seluruh katalog).
Database & Indexing:
- Menyimpan struktur data indeks terbalik (inverted index) dan metrik panjang produk ke database PostgreSQL untuk perhitungan skor yang efisien.
Query & Retrieval Pipeline:
- Membersihkan kueri masukan dari pengguna dengan pipa pemrosesan yang sama.
- Mengambil kandidat produk yang cocok dari inverted index.
- Menghitung nilai relevansi BM25 menggunakan parameter tuning halus untuk menghasilkan bobot pencarian yang optimal.
- Mengurutkan dan menampilkan produk pada E-Commerce Search UI.
2. Memahami Logika Matematika Okapi BM25
Okapi BM25 meningkatkan TF-IDF dengan memperkenalkan batas saturasi istilah (term saturation) dan normalisasi panjang dokumen (document length normalization).
Berikut adalah bagan logika matematika serta perbandingan antara BM25 dengan TF-IDF standar:
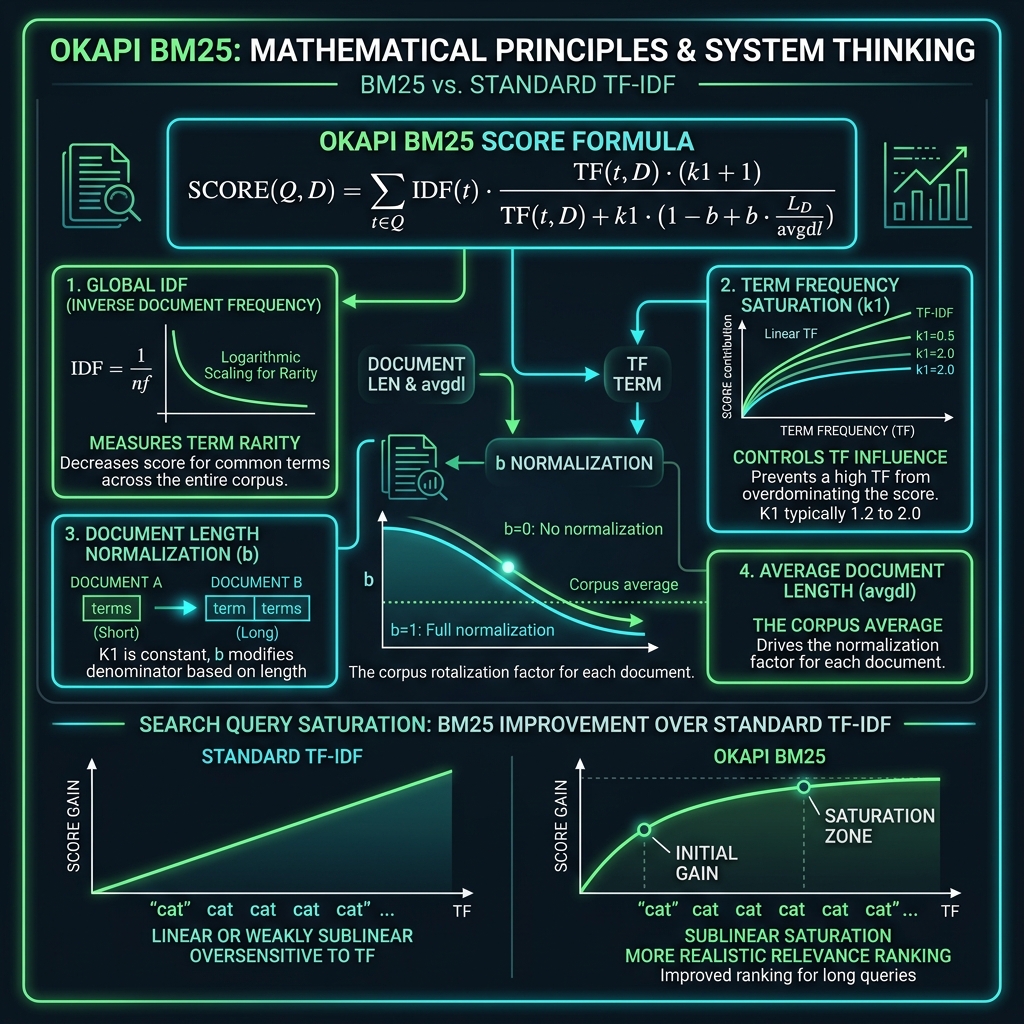
Rumus perhitungan skor relevansi Okapi BM25 untuk kueri $Q$ terhadap dokumen $D$ didefinisikan sebagai berikut:
$$\text{Score}(D, Q) = \sum_{i=1}^{n} IDF(q_i) \cdot \frac{f(q_i, D) \cdot (k_1 + 1)}{f(q_i, D) + k_1 \cdot \left(1 - b + b \cdot \frac{|D|}{\text{avgdl}}\right)}$$
Penjelasan Parameter Kunci:
- $f(q_i, D)$: Frekuensi kemunculan kata kunci $q_i$ di dalam dokumen produk $D$.
- $|D|$: Panjang dokumen (jumlah kata dalam deskripsi produk $D$).
- $\text{avgdl}$: Rata-rata panjang dokumen dari seluruh produk di dalam katalog (corpus).
- $k_1$ (Term Frequency Saturation): Mengontrol seberapa besar pengaruh pengulangan kata kunci terhadap skor. Nilai yang umum digunakan adalah antara $1.2$ hingga $2.0$. Nilai ini mencegah kata kunci yang ditulis berulang-ulang (keyword stuffing) mendominasi peringkat. Di atas batas saturasi, tambahan kemunculan kata tidak lagi meningkatkan skor relevansi secara signifikan.
- $b$ (Document Length Normalization): Mengontrol seberapa besar ukuran panjang dokumen mempengaruhi skor. Nilai umumnya adalah $0.75$. Nilai ini memberikan sanksi bagi produk dengan deskripsi yang sangat panjang namun tidak fokus pada kata kunci pencarian.
- $IDF(q_i)$: Mengukur keunikan istilah pencarian secara global. Dihitung dengan rumus: $$IDF(q_i) = \log\left(\frac{N - n(q_i) + 0.5}{n(q_i) + 0.5} + 1\right)$$ di mana $N$ adalah total produk dalam katalog, dan $n(q_i)$ adalah jumlah produk yang mengandung kata $q_i$.
3. Skema Database PostgreSQL untuk BM25
Untuk menghitung skor BM25 secara dinamis, PostgreSQL harus menyimpan metrik panjang tiap dokumen produk serta statistik rata-rata seluruh dokumen. Kita dapat membuat skema tabel berikut:
-- Menyimpan data produk e-commerce
CREATE TABLE products (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
description TEXT NOT NULL,
price DECIMAL(10,2) NOT NULL,
image_url VARCHAR(255),
document_length INT DEFAULT 0, -- Jumlah kata setelah preprocessing
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Menyimpan vocabulary global
CREATE TABLE bm25_dictionary (
term VARCHAR(100) PRIMARY KEY,
document_count INT DEFAULT 1
);
-- Menyimpan indeks terbalik dan term frequency
CREATE TABLE bm25_inverted_index (
product_id INT REFERENCES products(id) ON DELETE CASCADE,
term VARCHAR(100) REFERENCES bm25_dictionary(term) ON DELETE CASCADE,
tf INT NOT NULL, -- Raw Term Frequency
PRIMARY KEY (product_id, term)
);
-- Menyimpan nilai rata-rata panjang dokumen (avgdl) global
CREATE TABLE corpus_stats (
id INT PRIMARY KEY DEFAULT 1,
total_documents INT DEFAULT 0,
total_length BIGINT DEFAULT 0,
avg_length DOUBLE PRECISION DEFAULT 0.0,
CONSTRAINT single_row CHECK (id = 1)
);
-- Inisialisasi tabel statistik tunggal
INSERT INTO corpus_stats (id, total_documents, total_length, avg_length)
VALUES (1, 0, 0, 0.0)
ON CONFLICT DO NOTHING;
-- Indexing untuk mempercepat lookup term
CREATE INDEX idx_bm25_inverted_index_term ON bm25_inverted_index(term);
4. Implementasi Kode Preprocessing & Indexing (TypeScript)
Kita akan membuat kode pengindeks produk e-commerce yang menghitung panjang deskripsi produk dan memperbarui rata-rata panjang dokumen (avgdl) di database global secara otomatis.
import { Client } from 'pg';
export class TextPreprocessor {
private static readonly STOPWORDS = new Set([
'yang', 'dan', 'di', 'dari', 'dengan', 'ke', 'ini', 'itu', 'atau',
'the', 'is', 'at', 'which', 'on', 'for', 'a', 'an', 'in', 'to'
]);
public static clean(text: string): string[] {
return text
.toLowerCase()
.replace(/[^a-zA-Z0-9\s]/g, '')
.split(/\s+/)
.filter(token => token.length > 1 && !this.STOPWORDS.has(token));
}
}
export class ProductIndexer {
private db: Client;
constructor(dbClient: Client) {
this.db = dbClient;
}
public async indexProduct(name: string, description: string, price: number, imageUrl: string): Promise<void> {
// 1. Gabungkan nama dan deskripsi produk untuk diproses
const fullText = `${name} ${description}`;
const tokens = TextPreprocessor.clean(fullText);
const docLength = tokens.length;
if (docLength === 0) return;
// Hitung frekuensi mentah (tf)
const termCounts: Record<string, number> = {};
for (const token of tokens) {
termCounts[token] = (termCounts[token] || 0) + 1;
}
// Mulai Transaksi SQL
await this.db.query('BEGIN');
try {
// 2. Simpan produk ke tabel products
const productResult = await this.db.query(
`INSERT INTO products (name, description, price, image_url, document_length)
VALUES ($1, $2, $3, $4, $5) RETURNING id`,
[name, description, price, imageUrl, docLength]
);
const productId = productResult.rows[0].id;
// 3. Simpan kata-kata ke dictionary dan inverted index
for (const [term, tf] of Object.entries(termCounts)) {
await this.db.query(
`INSERT INTO bm25_dictionary (term, document_count)
VALUES ($1, 1)
ON CONFLICT (term)
DO UPDATE SET document_count = bm25_dictionary.document_count + 1`,
[term]
);
await this.db.query(
`INSERT INTO bm25_inverted_index (product_id, term, tf)
VALUES ($1, $2, $3)`,
[productId, term, tf]
);
}
// 4. Update statistik corpus global (N, total_length, avg_length)
await this.db.query(
`UPDATE corpus_stats
SET total_documents = total_documents + 1,
total_length = total_length + $1,
avg_length = (total_length + $1)::double precision / (total_documents + 1)::double precision
WHERE id = 1`,
[docLength]
);
await this.db.query('COMMIT');
} catch (error) {
await this.db.query('ROLLBACK');
throw error;
}
}
}
5. Implementasi Algoritma Pencarian & Scoring BM25
Saat pengguna mencari produk, kita memproses query, lalu menghitung relevansi BM25 dengan query SQL berkinerja tinggi yang mengeksekusi rumus matematika BM25 secara langsung pada database relasional.
Berikut adalah diagram alur kalkulasi pencarian langkah demi langkah:
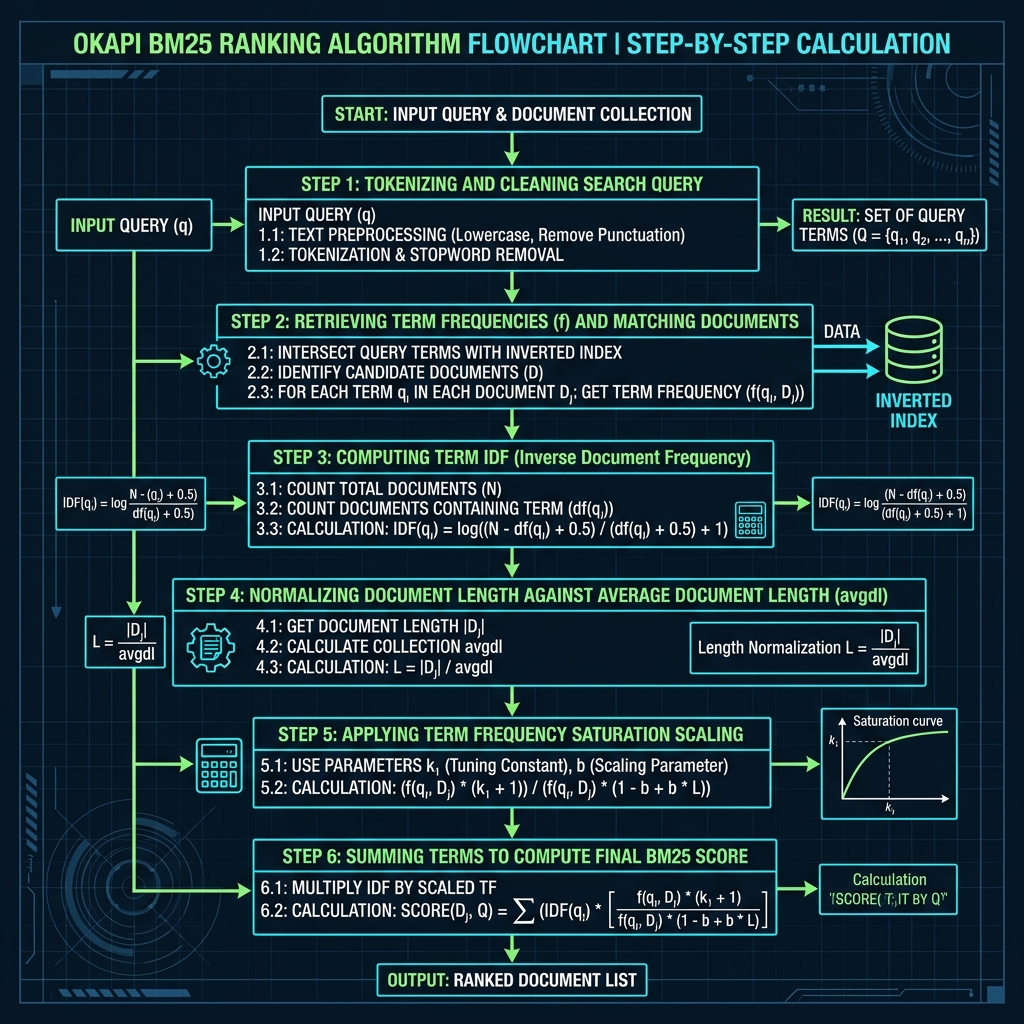
Query SQL di bawah ini menggunakan parameter standar $k_1 = 1.2$ dan $b = 0.75$:
export interface ProductSearchResult {
productId: number;
name: string;
description: string;
price: number;
imageUrl: string;
score: number;
}
export class ProductSearchEngine {
private db: Client;
constructor(dbClient: Client) {
this.db = dbClient;
}
public async search(queryText: string, limit: number = 6): Promise<ProductSearchResult[]> {
const queryTokens = TextPreprocessor.clean(queryText);
if (queryTokens.length === 0) return [];
// Gunakan parameter standar BM25
const k1 = 1.2;
const b = 0.75;
const sqlQuery = `
WITH query_terms AS (
SELECT unnest($1::text[]) AS term
),
stats AS (
SELECT total_documents AS N, avg_length AS avgdl FROM corpus_stats WHERE id = 1
),
term_idf AS (
-- Hitung IDF untuk setiap kata kunci dalam query
SELECT
qt.term,
-- IDF = ln((N - document_count + 0.5) / (document_count + 0.5) + 1)
LN((s.N - COALESCE(d.document_count, 0) + 0.5) / (COALESCE(d.document_count, 0) + 0.5) + 1.0) AS idf
FROM query_terms qt
CROSS JOIN stats s
LEFT JOIN bm25_dictionary d ON qt.term = d.term
),
product_scores AS (
-- Hitung nilai BM25 tiap produk
SELECT
ii.product_id,
SUM(
ti.idf * (
(ii.tf * ($2 + 1.0)) /
(ii.tf + $2 * (1.0 - $3 + $3 * (p.document_length::double precision / s.avgdl)))
)
) AS bm25_score
FROM bm25_inverted_index ii
JOIN term_idf ti ON ii.term = ti.term
JOIN products p ON ii.product_id = p.id
CROSS JOIN stats s
GROUP BY ii.product_id, p.document_length, s.avgdl
)
-- Ambil data produk teratas berdasarkan skor relevansi BM25
SELECT
p.id,
p.name,
p.description,
p.price,
p.image_url,
ps.bm25_score AS score
FROM product_scores ps
JOIN products p ON ps.product_id = p.id
ORDER BY score DESC
LIMIT $4;
`;
const result = await this.db.query(sqlQuery, [queryTokens, k1, b, limit]);
return result.rows.map(row => ({
productId: row.id,
name: row.name,
description: row.description,
price: parseFloat(row.price),
imageUrl: row.image_url,
score: parseFloat(row.score)
}));
}
}
6. Desain UI Halaman Hasil Pencarian Produk E-Commerce
Untuk menyajikan hasil pencarian produk secara premium, kita dapat menggunakan rancangan antarmuka E-Commerce dengan TailwindCSS bertema gelap modern berikut:
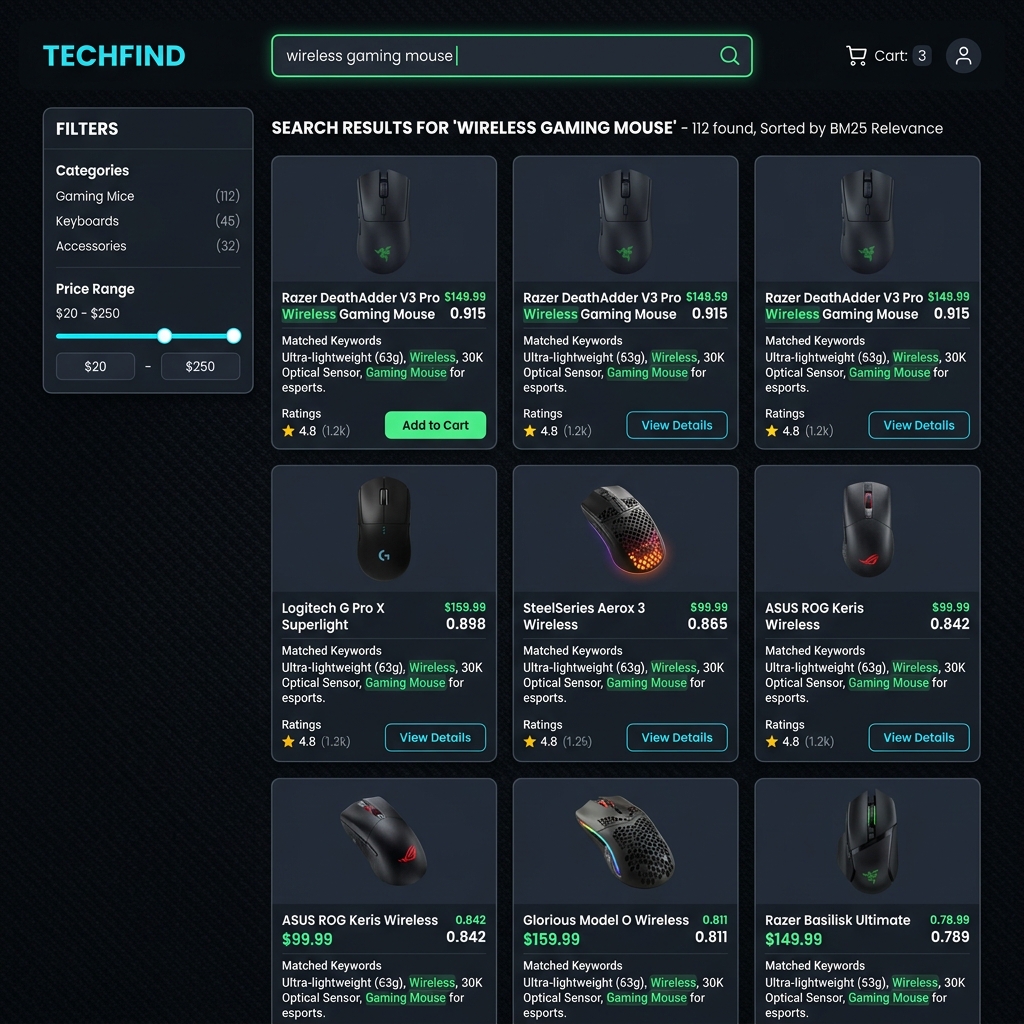
Implementasi struktur HTML/CSS static menggunakan kelas utilitas TailwindCSS:
<div class="min-h-screen bg-neutral-950 text-neutral-100 font-sans">
<!-- Top Navigation -->
<nav class="border-b border-neutral-900 bg-neutral-950 px-8 py-4 flex items-center justify-between">
<div class="text-xl font-bold tracking-wider text-cyan-400">TECHFIND</div>
<!-- Search Input -->
<div class="w-1/3 relative">
<input
type="text"
value="wireless gaming mouse"
class="w-full bg-neutral-900 border border-neutral-800 text-white rounded-lg px-4 py-2 focus:outline-none focus:border-cyan-500"
/>
<span class="absolute right-3 top-2.5 text-neutral-500">🔍</span>
</div>
<div class="flex items-center space-x-6 text-sm text-neutral-400">
<span>Cart (3)</span>
<span>Profile</span>
</div>
</nav>
<div class="max-w-7xl mx-auto px-8 py-6 grid grid-cols-4 gap-8">
<!-- Sidebar Filters -->
<aside class="col-span-1 space-y-6 bg-neutral-900/50 p-6 rounded-lg border border-neutral-900">
<h3 class="font-bold text-lg text-white">Filters</h3>
<!-- Category Filter -->
<div class="space-y-2">
<h4 class="text-xs font-semibold text-neutral-400 uppercase tracking-wider">Categories</h4>
<div class="space-y-1 text-sm">
<label class="flex items-center space-x-2 text-cyan-400">
<input type="checkbox" checked class="rounded border-neutral-800 bg-neutral-900 text-cyan-500 focus:ring-0" />
<span>Gaming Mice (112)</span>
</label>
<label class="flex items-center space-x-2 text-neutral-400">
<input type="checkbox" class="rounded border-neutral-800 bg-neutral-900 text-cyan-500 focus:ring-0" />
<span>Keyboards (45)</span>
</label>
</div>
</div>
</aside>
<!-- Product Grid -->
<main class="col-span-3 space-y-6">
<div class="flex justify-between items-center">
<h2 class="text-sm text-neutral-400">Search results for <span class="text-white font-semibold">"wireless gaming mouse"</span> - Sorted by BM25 Relevance</h2>
</div>
<div class="grid grid-cols-3 gap-6">
<!-- Product Card -->
<div class="bg-neutral-900 border border-neutral-900 rounded-lg p-4 space-y-4 hover:border-neutral-800 transition duration-200">
<div class="bg-neutral-950 aspect-video rounded-md flex items-center justify-center text-xs text-neutral-500 relative overflow-hidden">
<span>Mouse Image</span>
<!-- BM25 Score Tag -->
<div class="absolute top-2 right-2 bg-cyan-950 text-cyan-400 border border-cyan-800 text-xs font-mono font-bold px-2 py-0.5 rounded-full">
Score: 0.915
</div>
</div>
<div class="space-y-1">
<div class="flex justify-between items-start">
<h3 class="font-bold text-white text-sm">Razer DeathAdder V3 Pro</h3>
<span class="text-cyan-400 text-xs font-mono font-semibold">$149.99</span>
</div>
<p class="text-neutral-400 text-xs leading-relaxed">
Ultra-lightweight (63g), <span class="text-emerald-400 font-semibold">wireless</span> 30K Optical Sensor gaming mouse for esports.
</p>
</div>
<button class="w-full bg-cyan-600 hover:bg-cyan-500 text-neutral-950 font-bold py-2 rounded text-xs transition duration-200">
Add to Cart
</button>
</div>
</div>
</main>
</div>
</div>
7. Kelebihan Okapi BM25 Dibandingkan TF-IDF
BM25 disukai di lingkungan e-commerce karena memiliki kestabilan pencarian yang lebih baik:
- Saturasi Frekuensi Term (Term Frequency Saturation): Pada TF-IDF, nilai relevansi terus meningkat linier seiring pengulangan kata kunci. Pada BM25, pengaruh pengulangan kata melengkung (saturate) mendekati batas asimtotik tertentu ($k_1$). Ini menghentikan seller nakal yang melakukan spamming kata kunci pada deskripsi produk.
- Kompensasi Deskripsi Panjang (Length Normalization): Deskripsi produk yang pendek (seperti nama produk atau ringkasan spesifikasi) berbobot lebih tinggi dibandingkan deskripsi blog produk yang panjang dan bertele-tele jika kata kunci yang dicari muncul di dalamnya.
Referensi & Resource Penting
- Robertson, S. E., & Walker, S. (1994). Some simple effective approximations to the 2-Poisson model for probabilistic weighted retrieval. Analisis detail awal mengenai perancangan awal model BM25.
- PostgreSQL Full Text Search Documentation. Panduan lengkap pengindeksan teks bawaan PostgreSQL: PostgreSQL FTS Docs.
- Elasticsearch Reference: BM25 Similarity. Penjelasan implementasi default BM25 di mesin pencari industri modern: Elasticsearch BM25 Guide.
- Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to Information Retrieval. Buku teks standar akademik untuk memahami Information Retrieval dan Vector Space Models.