Banyak perusahaan menyebarkan survei kepuasan pelanggan bulanan guna mengevaluasi kualitas layanan mereka. Namun, salah satu tantangan terbesar dari survey kualitatif adalah keengganan responden untuk menulis jawaban deskriptif mengenai sentimen mereka. Membaca ribuan ulasan ulasan teks secara manual setiap bulan juga merupakan pekerjaan yang tidak efisien bagi tim Customer Service.
Untuk mengatasinya, kita dapat membangun sistem klasifikasi kepuasan otomatis menggunakan algoritma Logistic Regression.
Ide dasarnya sangat praktis:
- Variabel Input ($X$): Jawaban kuantitatif skala 1-5 pada pertanyaan operasional seperti "Kecepatan merespons", "Kemudahan penggunaan", dan "Kesesuaian harga".
- Hasil Output ($Y$): Nilai probabilitas (skala 0 sampai 1) apakah pelanggan ini masuk ke dalam kategori Berisiko Pindah ke Kompetitor (Churn) atau Pelanggan Setia (Loyal).
Dengan sistem ini, tim Customer Service dapat langsung memfilter dan menelepon pelanggan dengan risiko churn tertinggi sebelum mereka benar-benar meninggalkan layanan Anda.
Artikel ini akan membahas arsitektur sistem, dasar matematika fungsi sigmoid, skema database MySQL, implementasi inferensi model menggunakan PHP, dan antarmuka dashboard monitoring menggunakan TailwindCSS.
1. Arsitektur Sistem Klasifikasi Kepuasan Survey
Sistem ini memisahkan proses pengumpulan survey, kalkulasi inferensi machine learning, dan visualisasi tindak lanjut Customer Service.
Berikut adalah blueprint arsitektur sistem klasifikasi kepuasan survey berbasis Logistic Regression:
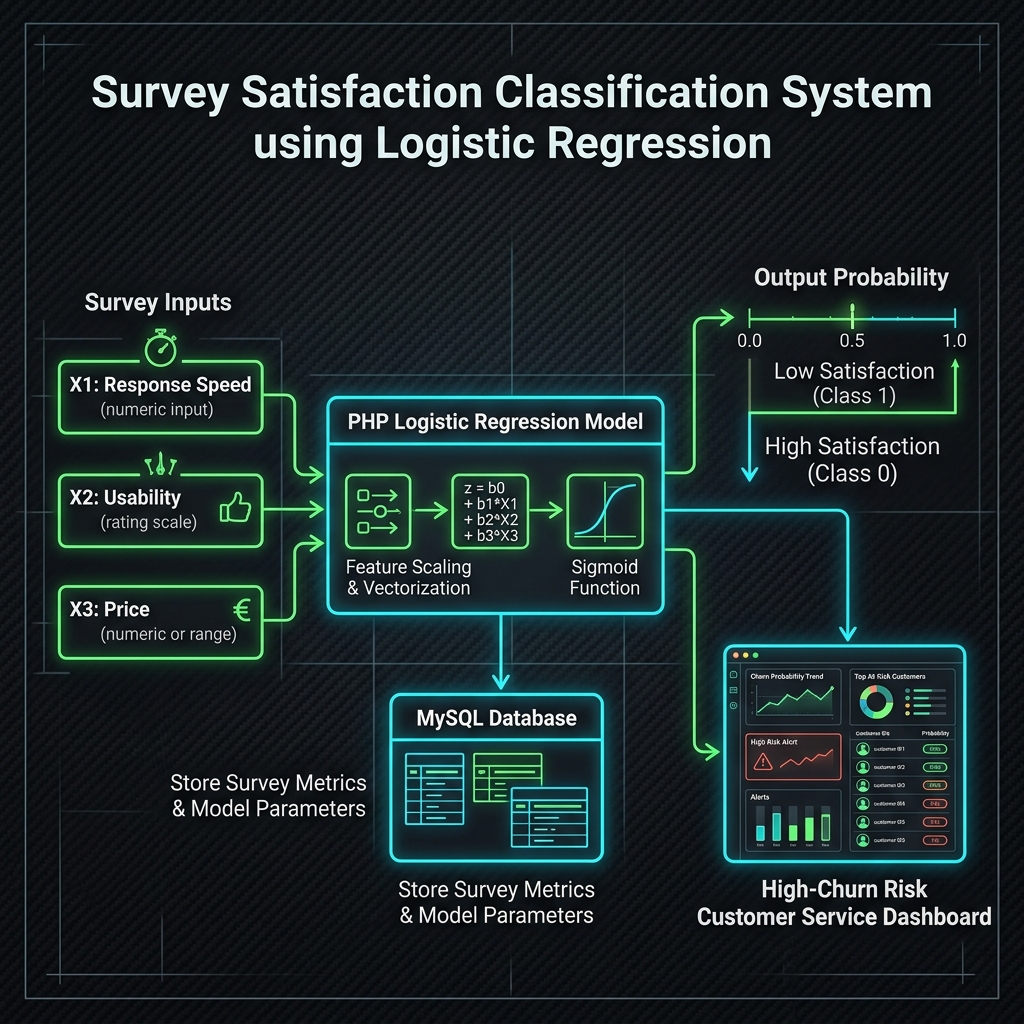
Alur Kerja Aliran Data:
- Survey Inputs: Responden mengisi nilai peringkat 1-5 pada parameter operasional ($X_1$: Speed, $X_2$: Usability, $X_3$: Price).
- PHP Logistic Regression Model: Backend PHP mengambil parameter model yang telah dilatih (weights dan bias) dari database, melakukan feature scaling, dan menghitung probabilitas menggunakan fungsi aktivasi sigmoid.
- MySQL Database: Menyimpan data respons mentah, metadata responden, serta nilai probabilitas hasil klasifikasi.
- High-Churn Risk Dashboard: Halaman khusus bagi tim Customer Service yang menampilkan daftar pelanggan paling tidak puas secara real-time berdasarkan prediksi model.
2. Logika Matematika & Fungsi Sigmoid
Logistic Regression memetakan hubungan linier antara variabel prediktor dengan log-odds dari probabilitas terjadinya suatu kejadian.
Berikut adalah diagram sistem matematika Logistic Regression:
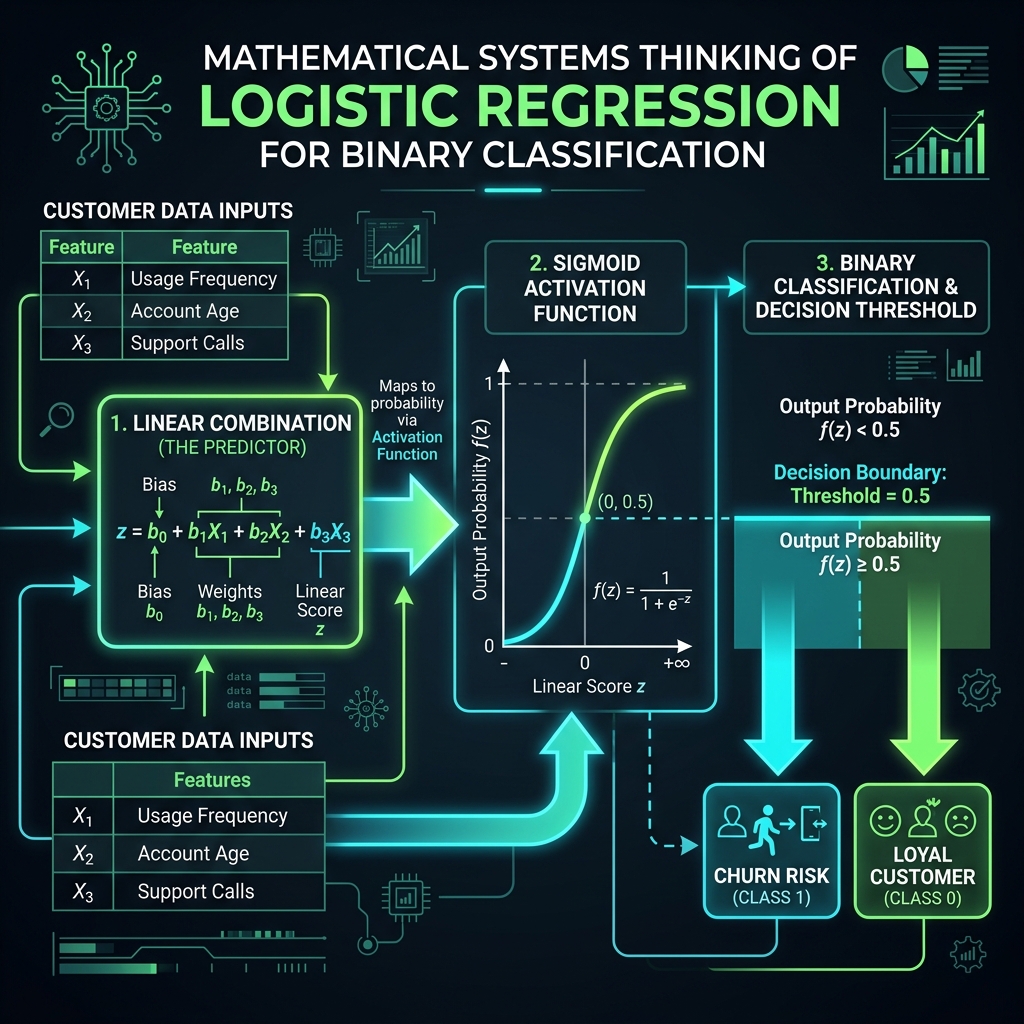
Rumus Perhitungan Probabilitas:
Pertama, hitung kombinasi linier dari fitur masukan menggunakan bobot (weight $w_i$) dan bias ($b$):
$$z = b + w_1 X_1 + w_2 X_2 + w_3 X_3$$
Kedua, masukkan nilai $z$ ke dalam fungsi aktivasi Sigmoid Function ($\sigma(z)$) untuk memetakan nilainya ke dalam rentang probabilitas $[0, 1]$:
$$p = \sigma(z) = \frac{1}{1 + e^{-z}}$$
Di mana:
- $p$ adalah probabilitas responden berisiko churn (Class 1).
- $1 - p$ adalah probabilitas responden setia (Class 0).
- Threshold (Ambang Batas) standar yang digunakan adalah $0.5$. Jika $p \ge 0.5$, maka pelanggan masuk dalam klasifikasi high-risk churn.
3. Skema Database MySQL
MySQL digunakan untuk mencatat data survei masuk, riwayat klasifikasi, serta tabel konfigurasi parameter model yang telah melalui fase offline training:
-- Menyimpan data respon survey pelanggan
CREATE TABLE survey_responses (
id INT AUTO_INCREMENT PRIMARY KEY,
customer_name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL,
score_speed INT NOT NULL, -- Fitur X1 (skala 1-5)
score_usability INT NOT NULL, -- Fitur X2 (skala 1-5)
score_price INT NOT NULL, -- Fitur X3 (skala 1-5)
churn_probability DOUBLE, -- Hasil output Y (probabilitas)
is_high_risk TINYINT(1), -- Flag klasifikasi (1 jika probabilitas >= 0.5)
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Menyimpan bobot parameter model hasil training (Weights & Bias)
CREATE TABLE model_parameters (
id INT AUTO_INCREMENT PRIMARY KEY,
feature_name VARCHAR(50) UNIQUE NOT NULL, -- 'speed', 'usability', 'price', 'bias'
weight_value DOUBLE NOT NULL
);
-- Inisialisasi parameter model tiruan hasil offline training
INSERT INTO model_parameters (feature_name, weight_value) VALUES
('speed', -0.85), -- Kecepatan rendah menaikkan peluang churn (bobot negatif)
('usability', -0.62), -- Usability buruk menaikkan peluang churn
('price', -0.45), -- Harga mahal menaikkan peluang churn
('bias', 3.20); -- Nilai intercept (bias)
4. Implementasi Klasifikasi Kepuasan (PHP)
Modul PHP berikut bertanggung jawab mengambil bobot dari database MySQL, menormalisasi data survei, menghitung persamaan regresi logistik, dan menghasilkan prediksi klasifikasi:
<?php
class LogisticRegressionModel {
private $pdo;
private $weights = [];
private $bias = 0.0;
public function __construct(PDO $pdo) {
$this->pdo = $pdo;
$this->loadModelParameters();
}
// Mengambil weights dan bias dari database
private function loadModelParameters() {
$stmt = $this->pdo->query("SELECT feature_name, weight_value FROM model_parameters");
$params = $stmt->fetchAll(PDO::FETCH_ASSOC);
foreach ($params as $param) {
if ($param['feature_name'] === 'bias') {
$this->bias = (double)$param['weight_value'];
} else {
$this->weights[$param['feature_name']] = (double)$param['weight_value'];
}
}
}
// Fungsi aktivasi Sigmoid
private function sigmoid($z) {
return 1.0 / (1.0 + exp(-$z));
}
// Melakukan inferensi untuk menghitung probabilitas churn
public function predict(int $speed, int $usability, int $price): array {
// 1. Skala masukan 1-5 diubah ke double (bisa ditambah feature scaling jika perlu)
$x1 = (double)$speed;
$x2 = (double)$usability;
$x3 = (double)$price;
// 2. Persamaan Linear Combinations (z = b + w1*X1 + w2*X2 + w3*X3)
$z = $this->bias +
($this->weights['speed'] * $x1) +
($this->weights['usability'] * $x2) +
($this->weights['price'] * $x3);
// 3. Kalkulasi probabilitas dengan Sigmoid Function
$probability = $this->sigmoid($z);
// 4. Binary Classification dengan Threshold 0.5
$isHighRisk = $probability >= 0.5 ? 1 : 0;
return [
'probability' => $probability,
'is_high_risk' => $isHighRisk
];
}
// Menyimpan survey baru sekaligus memprediksi skor churn
public function saveSurveyResponse(string $name, string $email, int $speed, int $usability, int $price) {
$prediction = $this->predict($speed, $usability, $price);
$stmt = $this->pdo->prepare("
INSERT INTO survey_responses (customer_name, email, score_speed, score_usability, score_price, churn_probability, is_high_risk)
VALUES (:name, :email, :speed, :usability, :price, :prob, :risk)
");
$stmt->execute([
'name' => $name,
'email' => $email,
'speed' => $speed,
'usability' => $usability,
'price' => $price,
'prob' => $prediction['probability'],
'risk' => $prediction['is_high_risk']
]);
return $prediction;
}
}
5. Flow Algoritma & Antarmuka Dashboard CS (TailwindCSS)
Saat survey masuk, sistem memproses data melalui siklus pemrosesan berikut dari offline training hingga klasifikasi langsung (real-time inference):
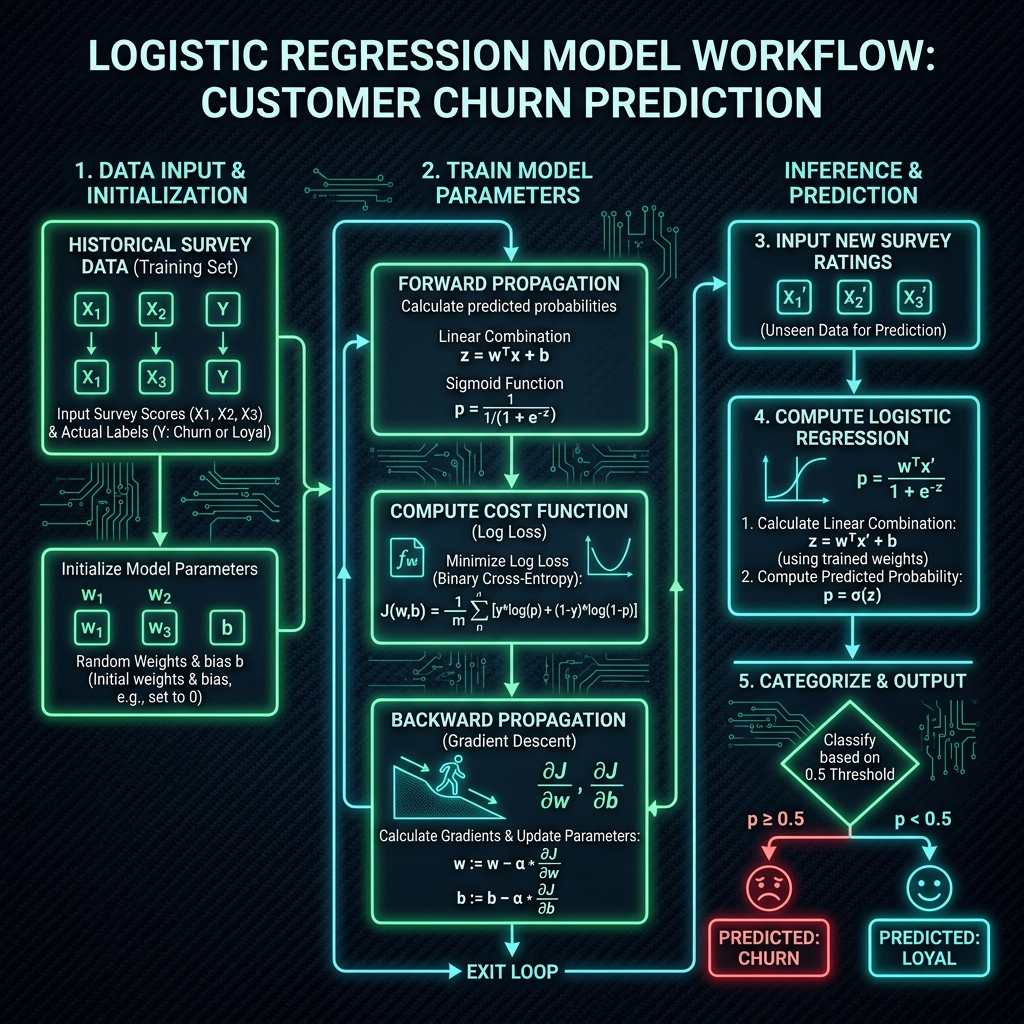
Untuk memudahkan tim Customer Service meninjau daftar pelanggan dengan tingkat urgensi tinggi, kita mendesain antarmuka dashboard minimalis menggunakan TailwindCSS:
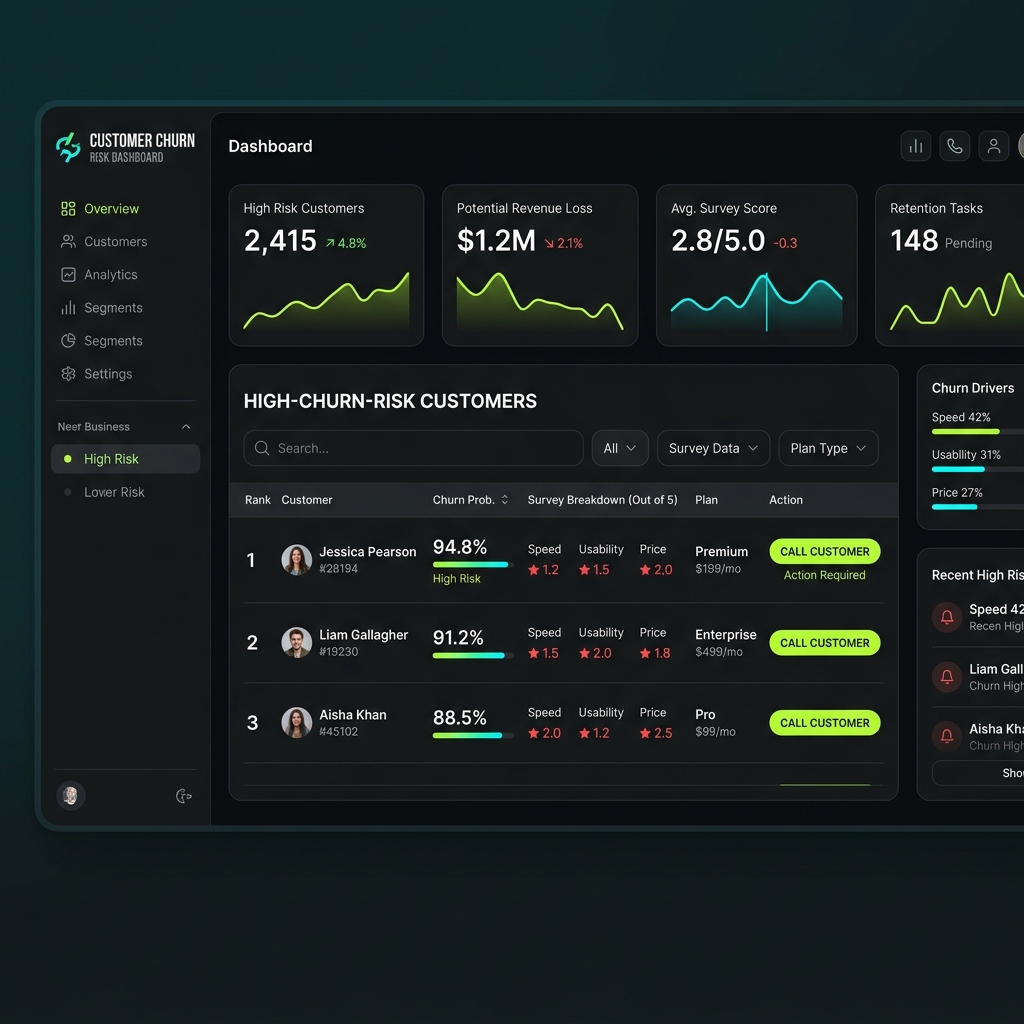
Implementasi struktur HTML static menggunakan kelas utilitas TailwindCSS:
<div class="min-h-screen bg-neutral-950 text-neutral-100 font-sans">
<!-- Main Grid Layout -->
<div class="flex">
<!-- Sidebar -->
<aside class="w-64 bg-neutral-900 min-h-screen p-6 border-r border-neutral-800 space-y-6">
<div class="flex items-center space-x-2">
<span class="text-cyan-400 text-2xl">📊</span>
<span class="font-bold text-lg text-white">ChurnRadar</span>
</div>
<nav class="space-y-1">
<a href="#" class="block px-4 py-2 bg-cyan-500/10 text-cyan-400 rounded-lg text-xs font-semibold">Overview</a>
<a href="#" class="block px-4 py-2 text-neutral-400 hover:text-white rounded-lg text-xs">High Risk Segment</a>
</nav>
</aside>
<!-- Main Content -->
<main class="flex-1 p-8 space-y-8">
<!-- Header -->
<header class="flex justify-between items-center">
<div>
<h2 class="text-2xl font-bold text-white">High Churn Risk Dashboard</h2>
<p class="text-xs text-neutral-400">Daftar pelanggan berisiko tinggi berdasarkan survei kepuasan</p>
</div>
</header>
<!-- Risk Table -->
<div class="bg-neutral-900 border border-neutral-800 rounded-lg overflow-hidden">
<table class="w-full text-left text-xs border-collapse">
<thead>
<tr class="bg-neutral-950 border-b border-neutral-800 text-neutral-400 uppercase tracking-wider">
<th class="p-4">Customer</th>
<th class="p-4">Churn Probability</th>
<th class="p-4">Survey Scores (Out of 5)</th>
<th class="p-4 text-right">Action</th>
</tr>
</thead>
<tbody class="divide-y divide-neutral-800 text-neutral-300">
<tr>
<td class="p-4">
<div class="font-bold text-white">Jessica Pearson</div>
<div class="text-[10px] text-neutral-500">jessica@pearson.com</div>
</td>
<td class="p-4">
<div class="flex items-center space-x-2">
<span class="text-rose-400 font-mono font-bold">94.8%</span>
<span class="bg-rose-950/50 text-rose-400 border border-rose-900 px-2 py-0.5 rounded text-[10px]">High Risk</span>
</div>
</td>
<td class="p-4">
Speed: <span class="text-red-400">1.2</span> | Usability: <span class="text-red-400">1.5</span> | Price: <span class="text-yellow-400">2.0</span>
</td>
<td class="p-4 text-right">
<button class="bg-rose-600 hover:bg-rose-500 text-white font-bold px-3 py-1.5 rounded transition">
📞 Call Customer
</button>
</td>
</tr>
</tbody>
</table>
</div>
</main>
</div>
</div>
6. Mengapa Logistic Regression Tepat untuk Survey Kepuasan?
Pendekatan model probabilistik ini memberikan keuntungan operasional yang terukur:
- Output Berupa Probabilitas Kontinu: Logistic regression tidak hanya menebak label ya/tidak secara mentah, namun memberikan probabilitas yang halus (seperti $94.8%$). Ini mempermudah tim CS melakukan prioritas kerja berdasarkan urutan keparahan.
- Kemudahan Interpretasi (Interpretability): Nilai bobot (weights) mencerminkan tingkat pengaruh masing-masing parameter. Contoh, bobot $w_1 = -0.85$ (Speed) lebih negatif dibanding $w_3 = -0.45$ (Price), menunjukkan bahwa kecepatan respons jauh lebih berpengaruh dalam mempertahankan pelanggan daripada masalah harga.
Referensi & Resource Penting
- Hosmer, D. W., Lemeshow, S., & Sturdivant, R. X. (2013). Applied Logistic Regression (3rd ed.). Wiley. Buku rujukan klasik paling lengkap mengenai analisis regresi logistik.
- PHP Mathematical Functions. Dokumentasi fungsi eksponen dan matematika bawaan PHP: PHP Math Docs.
- MySQL Mathematical Functions. Informasi fungsi matematika database MySQL: MySQL Math Reference.
- Ng, Andrew. Machine Learning Specialization. Stanford University / Coursera. Modul perkuliahan komprehensif mengenai konsep dasar Gradient Descent dan Cost Function (Log Loss) pada klasifikasi biner.